Appearance
PHP
php5和php7区别?
- 性能提升:PHP 7 相比 PHP 5 在性能上有了显著的提升。在同样的硬件条件下,PHP 7 的处理能力是 PHP 5 的两倍以上。
- 新的 Zend 引擎:PHP 7 使用了全新的 Zend 引擎——Zend Engine 3,而 PHP 5 使用的是 Zend Engine 2。
- 错误处理:PHP 7 引入了新的对象类型 Throwable,使得错误处理变得更加灵活。
- 类型声明:PHP 7 增加了标量类型(如:int,float,string,bool)和返回类型声明,这让 PHP 支持更严谨的编程方式。
- 新的运算符:PHP 7 引入了 null 合并运算符(??)和太空船运算符(<=>),提高了代码的可读性和编写的便捷性。
- 匿名类:PHP 7 增加了对匿名类的支持,这在编写测试代码或者需要临时创建一个新类的场景中非常有用。
- 废弃的特性:PHP 7 废弃了一些 PHP 5 的旧特性,例如原始的 MySQL 扩展,ereg 正则表达式函数等。
- 更严格的类型比较:PHP 7 在 == 运算符的类型比较上更严格,避免了一些因为宽松比较造成的问题。
PHP7和PHP8的区别?
命名参数:仅仅指定必填参数,跳过可选参数。参数的顺序无关、自己就是文档(self-documented)
注解:现在可以用 PHP 原生语法来使用结构化的元数据,而非 PHPDoc 声明。
构造器属性提升:更少的样板代码来定义并初始化属性。
联合类型:相较于以前的 PHPDoc 声明类型的组合, 现在可以用原生支持的联合类型声明取而代之,并在运行时得到校验。
Match 表达式:新的 match 类似于 switch,并具有以下功能: Match 是一个表达式,它可以储存到变量中亦可以直接返回。Match 分支仅支持单行,它不需要一个 break; 语句。 Match 使用严格比较。
即时编译:PHP 8 引入了两个即时编译引擎。 Tracing JIT 在两个中更有潜力,它在综合基准测试中显示了三倍的性能, 并在某些长时间运行的程序中显示了 1.5-2 倍的性能改进。 典型的应用性能则和 PHP 7.4 不相上下。
只读类:禁止创建动态属性,readonly类只能被readonly类继承;
析取范式 (DNF)类型:DNF 类型允许我们组合 union 和 intersection类型,遵循一个严格规则:组合并集和交集类型时,交集类型必须用括号进行分组。
允许 null、false 和 true 作为独立类型:
**Traits 中的常量 **:
弃用动态属性:动态属性的创建已被弃用,以帮助避免错误和拼写错误,除非该类通过使用 #[\AllowDynamicProperties] 属性来选择。stdClass 允许动态属性。__get/__set 魔术方法的使用不受此更改的影响。
8.1:枚举,只读属性,
8.2:只读类,弃用动态属性,要写注解才可
8.3:#[\Override]来说明覆盖父类的方法,
PHP代码的执行过程是怎样的?
PHP代码的执行过程可以分为以下几个步骤:
- 解析(Parsing):PHP代码首先需要被解析器解析。解析器将源代码转换为内部表示形式,即抽象语法树(Abstract Syntax Tree,AST)。
- 编译(Compilation):解析后的代码被编译成字节码。PHP引擎将抽象语法树转换为可执行的中间代码(Opcode)。
- 执行(Execution):PHP引擎执行编译后的字节码。代码逐行执行,从顶部到底部按顺序执行。
- 运行时数据操作:在执行过程中,PHP引擎处理变量、函数调用、对象实例化等运行时数据操作。
- 输出结果:根据代码逻辑和运行时数据操作,PHP引擎生成相应的输出结果。这可以是网页内容、JSON数据、文件操作等。 需要注意的是,PHP是一种解释型语言,每次执行都需要经过解析、编译和执行的过程。在执行过程中,PHP引擎会根据需要动态加载和执行所需的函数和类。
php-fpm的运行模型?
多进程同步阻塞模式
php-fpm是一种master(主)/worker(子)多进程架构模型。
当PHP-FPM启动时,会读取配置文件,然后创建一个Master进程和若干个Worker进程(具体是几个Worker进程是由php-fpm.conf中配置的个数决定)。Worker进程是由Master进程fork出来的。
master进程主要负责CGI及PHP环境初始化、事件监听、Worker进程状态等等,worker进程负责处理php请求。
master进程负责创建和管理woker进程,同时负责监听listen连接,master进程是多路复用的;woker进程负责accept请求连接,同时处理请求,一个woker进程可以处理多个请求(复用,不需要每次都创建销毁woker进程,而是达到处理一定请求数后销毁重新fork创建worker进程),但一个woker进程一次只能处理一个请求。
php-fpm优化?静态方式如何确定最大 worker 数
①动态(Dynamic) listen = 127.0.0.1:9001 pm = dynamic #工作模式为动态 pm.max_children = 10 #pm 设置为 dynamic 时表示最大可创建的子进程的数量pm.start_servers = 2 #起始进程数 pm.min_spare_servers = 1 #最大空闲进程 pm.max_spare_servers = 6 #最小空闲进程 空闲进程数<pm.min_spare_servers时,创建新的子进程(数量<=pm.max_children,数量<=process.max) 空闲进程数>pm.max_spare_servers,会杀死启动时间最长的子进程 优点:动态扩容,不浪费系统资源,按设置最大空闲进程数来收回进程,内存开销小 缺点:当所有的worker都在工作,必须等待创建worker进程,频繁启动停止消耗cpu,请求数稳定不需要频繁销毁
②静态(static) pm = dynamic #工作模式为动态 pm.max_children = 10 #pm 设置为 static 时表示创建的子进程的数量 优点:性能相对较好 缺点:占用系统资源,一开始就固定进程数量了
③按需分配(ondemand ) 启动时不启动子进程,请求来了再启动 listen = 127.0.0.1:9001 pm = ondemand #工作模式为按需分配 pm.process_idle_timeout = 60 #秒数,多久之后结束空闲进程。仅当设置 pm为 ondemand pm.max_children = 10 # 优点:内存优先,有求再用 缺点:性能相对差
每个进程约m = 20M 动态:CPU核数+20% ~ 内存/每个进程内存 静态:内存/(每个进程内存*1.2) 参考文章 php文档
静态变量在内存什么地方?
PHP内存管理机制与垃圾回收机制
php的内存管理机制是:预先给出一块空间,用来存储变量,当空间不够时,再申请一块新的空间。
存储变量名,存在符号表。
变量值存储在内存空间。
在删除变量的时候,会将变量值存储的空间释放,而变量名所在的符号表不会减小。
php垃圾回收机制是:
在5.2版本或之前版本,PHP会根据 引用计数 (refcount)值来判断是不是垃圾,如果refcount值为0,PHP会当做垃圾释放掉,这种回收机制有缺陷,对于环状引用的变量无法回收。
在5.3之后版本改进了垃圾回收机制。具体如下:
如果发现一个zval容器中的refcount在增加,说明不是垃圾; 如果发现一个zval容器中的refcount在减少,如果减到了0,直接当做垃圾回收; 如果发现一个zval容器中的refcount在减少,并没有减到0,PHP会把该值放到缓冲区,当做有可能是垃圾的怀疑对象; 当缓冲区达到了临界值,PHP会自动调用一个方法去遍历每一个值,如果发现是垃圾就清理。
nginx和php-fpm的通信机制
CGI和fast-CGI
CGI:通用网关接口;每次请求都启动一个新的CGI脚本进程,效率慢;
fastcgi:快速的通用网关接口;用长期运行进程池(如 PHP-FPM);避免一直创建销毁进程
opcache
opcache通过将预编译的字节码存储到共享内存,来提升性能,减少每次的加载和解析
主要配置: opcache.enable:启用或禁用OPcache。设置为1以启用,或0以禁用。
opcache.memory_consumption:编译后的存储量。
opcache.interned_strings_buffer:设置用于存储内部字符串的内存量,这可以通过减少字符串重复来提高性能。
opcache.max_accelerated_files:可缓存的最大文件数。
opcache.revalidate_freq:脚本更新频率(秒)
opcache.validate_timestamps:如果启用,OPcache将检查脚本的时间戳以确定是否需要更新缓存。
opcache.save_comments:决定是否保存注释。
opcache.preload:PHP 7.4.0开始,可以设置预加载脚本的路径
PHP 数组底层数据结构,如何存储?扩容?
用hashTable+链表
用散列hash来计算出存储的索引;冲突了就保存在同一链表中
扩容:rehash
PHP 数组是怎么实现的?
赋值和引用传值
| 特性 | 赋值(Value Assignment) | 引用传值(Reference Assignment) |
|---|---|---|
| 符号 | = | & |
| 含义 | 将一个变量的值复制到另一个变量中 | 使两个变量引用同一个值的内存地址 |
| 独立性 | 独立的两个变量,修改一个不会影响另一个 | 修改其中一个变量会影响另一个 |
| 内存占用 | 每个变量都有自己的内存空间 | 两个变量引用同一个内存地址 |
| 示例 | $a = 5; $b = $a;($a和$b是两个独立的变量,都包含值5) | $a = 5; $b = &$a;($a和$b引用同一个内存地址,修改$a或$b都会影响对方) |
面向对象,OOP
面向对象编程(OOP)是一种编程范式,主要是通过“对象”概念来模型化现实世界中的事物。在 PHP 中,以下是面向对象编程的一些关键概念和特性:
- 继承:子类可以继承父类的属性和方法,实现代码重用。
- 封装:隐藏对象的内部实现细节,只提供有限的接口与外界交互。
- 多态:不同类的对象对同一消息会有不同的响应。也就是说,父类引用指向不同的子类对象时,调用相同的方法,可以呈现不同的行为。
- 访问修饰符:
public(公共成员,子类,外部,内部都可调用没有限制);protected(保护成员,子类,内部可调用);private(私有成员,内部可调用);
- 抽象类(
abstract):抽象类只能被继承,不能实例化。抽象类中可以定义抽象方法,子类必须实现这些抽象方法。
- final:如果一个类被声明为 final,那么它不能被继承。如果一个方法被声明为 final,那么子类不能覆盖这个方法。
- 接口(
interface):接口是一种规范,它定义了一些方法,实现接口的类必须实现这些方法。(implement)
- trait:Trait 是一种代码复用的机制。Trait 不能被实例化,它需要被类使用。
- 魔术方法:PHP 中有许多以双下划线(
__)开头的特殊方法,比如__construct(构造方法)、__destruct(析构方法)、__get(获取未定义的属性)、__set(设置未定义的属性)等。 __construct() 实例化类时自动调用。
__destruct() 类对象使用结束时自动调用。
__set() 在给未定义的属性赋值的时候调用。
__get() 调用未定义的属性时候调用。
__isset() 使用isset()或empty()函数时候会调用。
__unset() 使用unset()时候会调用。
__sleep() 使用serialize序列化时候调用。
__wakeup() 使用unserialize反序列化的时候调用。
__call() 调用一个不存在的方法的时候调用。
__callStatic()调用一个不存在的静态方法是调用。
__toString() 把对象转换成字符串的时候会调用。比如 echo。
__invoke() 当尝试把对象当方法调用时调用。
__set_state() 当使用var_export()函数时候调用。接受一个数组参数。
__clone() 当使用clone复制一个对象时候调用。$this,self,parent:$this代表当前对象,self代表当前类,parent代表父类。
abstract和interface的区别?
**抽象类(abstract class)和接口(interface)**都是面向对象编程中的高级特性,它们都不能被实例化,主要用于被其他类继承或实现。但是,它们之间存在一些关键的区别:
- 定义方式:抽象类使用关键字
abstract来定义,而接口使用关键字interface。
- 实现方式:子类使用
extends关键字来继承抽象类,使用implements关键字来实现接口。
- 方法定义:抽象类中可以有抽象方法和非抽象方法,抽象方法使用
abstract关键字声明,没有方法体;接口中只能有抽象方法,所有的方法默认都是public和abstract的,且不能有方法体。
- 属性:抽象类中可以定义属性,而接口中不能有属性。
- 实现数量:一个类只能继承一个抽象类,但是可以实现多个接口。
- 构造函数:抽象类可以有构造函数,而接口不能有。
- 访问修饰符:抽象类的方法可以是
public、protected或private,而接口的方法必须是public。
在选择使用抽象类还是接口时,如果多个类之间存在 "is-a" 关系(例如,猫和狗都是动物),通常使用抽象类;如果多个类之间存在 "has-a" 关系(例如,鸟可以飞,飞机也可以飞),通常使用接口。
构造数和普通函数的区别?
- 构造函数是在创建对象时自动调用的特殊方法,主要用于初始化对象。在PHP中,构造函数的名称为
__construct。构造函数不能有返回值,并且一个类中只能有一个构造函数。
- 普通函数则是类中的常规方法,可以有返回值,也可以没有。普通函数只在被明确调用时执行,而且一个类中可以有多个普通函数。
静态函数和非静态函数的区别?
1.静态方法属于类所有,可以在类实例化之前直接调用,无需创建对象实例。使用类名加上双冒号(::)来调用静态方法,例如ClassName::staticMethod()。
2.非静态方法需要通过对象实例来调用,可以访问类中的任何成员,包括静态成员和非静态成员。非静态方法不能直接通过类名调用。
3.静态方法在定义类时就已经加载和分配内存,而非静态方法只有在创建对象实例时才会被分配内存。
4.静态方法只能访问静态成员,不能访问非静态成员。非静态方法可以访问类中的所有成员。
5.静态方法内部不能使用 $this 关键字,因为 $this 是指向当前对象实例的指针,而静态方法没有对象实例。可以使用 self:: 关键字来访问当前类的静态成员。
6.静态方法在效率上比实例化对象后调用的非静态方法更高,因为静态方法的调用不涉及对象实例化和销毁的过程。
7.静态方法和静态变量共享同一块内存空间,而每个对象实例都会创建自己的内存空间。
静态函数在堆上还是栈上?
静态函数,像所有函数一样,都是在代码区存储的,这是程序的一部分。当我们说某些数据是存储在堆或栈上时,我们通常是指函数的变量和数据,而不是函数本身。局部变量存储在栈上,而动态分配的变量(如使用
new或malloc创建的变量)存储在堆上。至于静态变量,它们既不在堆上,也不在栈上,而是存储在全局/静态内存区域中。
设计模式
设计模式的原则
- 单一职责原则(Single Responsibility Principle,SRP):一个类只负责一个职责或者功能。不应该设计大而全的类,应该将功能分解到尽可能小的类中。
- 开放封闭原则(Open Closed Principle,OCP):软件实体(类、模块、函数)应当对扩展开放,对修改封闭。这意味着一个实体允许其行为被扩展,而无需修改其源代码。
- 里氏替换原则(Liskov Substitution Principle,LSP):所有引用父类的地方必须能透明地使用其子类对象。简单来说,子类对象能够替换父类对象,而程序逻辑不变。
- 依赖倒置原则(Dependence Inversion Principle,DIP):高层模块不应依赖于低层模块,两者都应依赖于抽象;抽象不应依赖于具体,具体应依赖于抽象。换言之,要针对接口编程,不要针对实现编程。
- 接口隔离原则(Interface Segregation Principle,ISP):使用多个专门的接口,而不使用单一的总接口。一个类对另一个类的依赖应该建立在最小的接口上。
- 合成复用原则(Composite Reuse Principle,CRP):尽量使用合成/聚合的方式,而不是使用继承。
- 迪米特法则(Law of Demeter,LOD):迪米特法则又叫作最少知识原则,一个类对于其他类知道的越少越好,就是说一个对象应当对其他对象有尽可能少的了解,只和朋友通信,不和陌生人说话。
前五个合称 SOLID原则(单一职责原则、开放关闭原则、里氏替换原则、接口隔离原则和依赖倒置原则)
composer
composer自动加载原理?
Composer 的自动加载功能依赖于 PHP 的
spl_autoload_register()函数。这个函数可以注册任意数量的自动加载器,当试图使用尚未被定义的类(或接口、特性)时,这些自动加载器会被逐一调用。 Composer 生成的自动加载器(通常位于vendor/autoload.php)会在运行时被包含进来。这个自动加载器包含了所有 Composer 知道的类、接口和特性的位置信息。当你试图使用一个尚未被定义的类时,Composer 的自动加载器就会根据其内部的映射关系,找到对应的文件,然后包含进来,从而实现类的自动加载。 Composer 支持以下四种自动加载规范:
- PSR-0:此规范已经被废弃,不推荐使用。但出于向后兼容性,Composer 仍然支持。
- PSR-4:这是目前最推荐使用的自动加载规范。它需要每个命名空间的前缀都映射到一个目录。
- 类映射:Composer 允许手动为每个类定义文件路径。
- 文件:Composer 允许手动包含特定文件,这些文件通常包含函数定义或者需要在每次请求时都运行的代码。
autoload_static.php,保存命名空间前缀和目录的映射关系,要类来对应的目录找
composer自动加载原理
php
include 'autoload.php';
ComposerAutoloaderInit::getLoader();
class ComposerAutoloaderInit
{
function getLoader()
{
//参数是vendor目录
self::$loader = $loader = new ClassLoader(\dirname(\dirname(__FILE__)));
call_user_func(ComposerStaticInit::getInitializer($loader));
$loader->register(true);
//需要自动加载的 .php文件
$includeFiles = Composer\Autoload\ComposerStaticInit::$files;
foreach ($includeFiles as $fileIdentifier => $file) {
composerRequire($fileIdentifier, $file);
}
}
}
class ClassLoader
{
private $vendorDir;
public function __construct($vendorDir = null)
{
$this->vendorDir = $vendorDir;
}
function register($prepend = false)
{ //自动加载
spl_autoload_register(array($this, 'loadClass'), true, $prepend);
//省略
//
self::$registeredLoaders = array($this->vendorDir => $this) + self::$registeredLoaders;
//省略
}
public function loadClass($class)
{
if ($file = $this->findFile($class)) {
includeFile($file);
return true;
}
return null;
}
public function findFile($class){
//找到类对应的文件
$this->classMap[$class];
}
}
class ComposerStaticInit
{
//类 ComposerStaticInit下的
static function getInitializer($loader)
{
//赋值
$loader->prefixLengthsPsr4 = ComposerStaticInit::$prefixLengthsPsr4;
$loader->prefixDirsPsr4 = ComposerStaticInit::$prefixDirsPsr4;
$loader->prefixesPsr0 = ComposerStaticInit::$prefixesPsr0;
$loader->classMap = ComposerStaticInit::$classMap;
}
}
function includeFile($file)
{
include $file;
}
//引入文件
function composerRequire($fileIdentifier, $file)
{
//省略逻辑...
require $file;
}Composer 锁定文件(composer.lock)的作用是什么?为什么重要?
Composer锁定文件(composer.lock)的作用
composer.lock文件是 Composer 在执行composer update命令时生成的一个快照文件。它记录了执行composer update命令时每个依赖包的确切版本号。这样,当运行composer install命令时,Composer 会查看composer.lock文件,并下载文件中指定的版本,而不是composer.json文件中定义的版本。为什么重要
composer.lock文件的存在,保证了无论你在何时、何地、何种环境下运行composer install命令,都能获取到相同版本的依赖包。这对于确保应用程序的一致性和可预测性非常重要,特别是在团队开发或者生产环境部署中。在开发过程中,你应该将
composer.lock文件提交到版本控制系统中。这样,当其他开发者或者 CI/CD 系统检出代码并运行composer install命令时,他们将会安装和你完全相同版本的依赖包。
laravel
laravel的生命周期
单一入口,public/index.php加载composer,初始化vendor目录下的; Container从bootstrap/app.php注册核心组件; 处理请求,加载配置,门面注册,服务提供者等; 全局中间件,命中路由。路由中间件,路由回调,响应
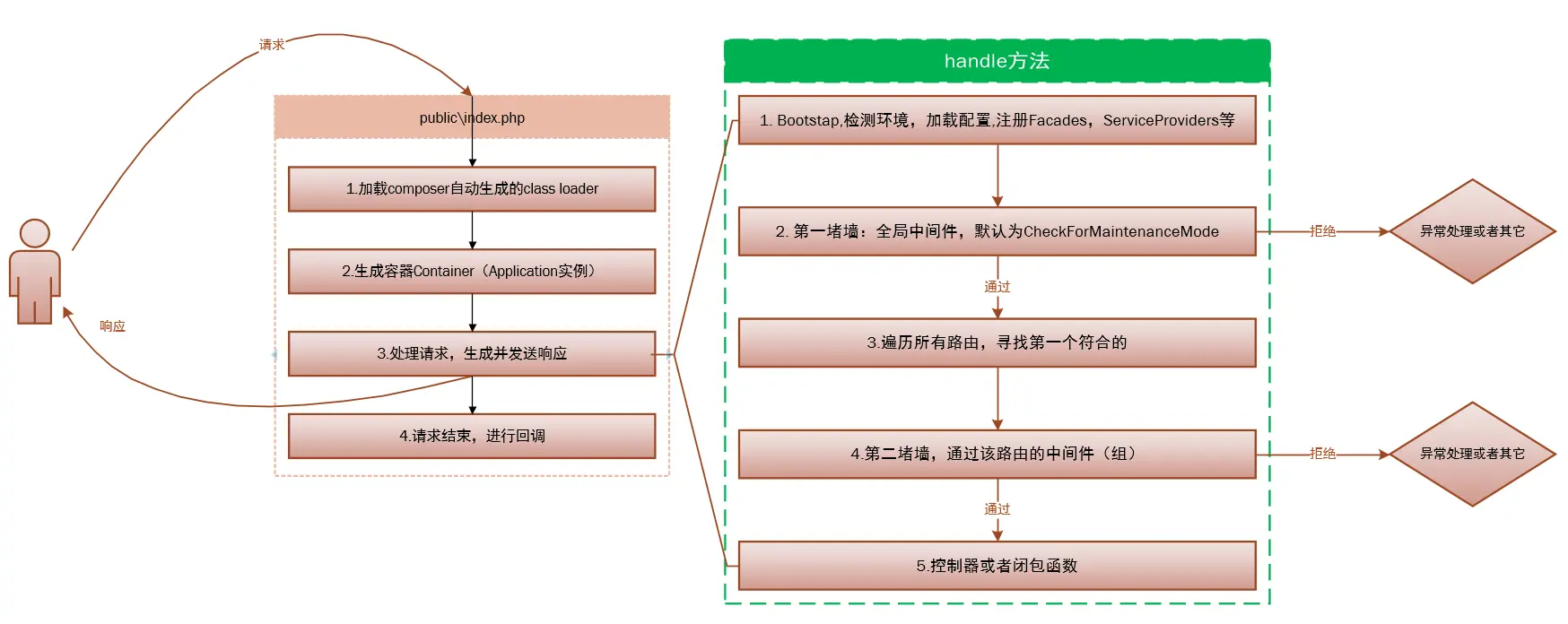
laravel 的声明周期都是从 public/index.php 开始,所有请求都会被 web 服务器导入到此文件中; 接下来,请求发送到 http 内核或者 console 内核(分别处理 web 请求和 artisan 命令。)内核请求过程中最重要的内容就是为应用载入服务提供者; 应用所有的服务提供者都被配置在 config/app 配置文件的 providers 数组中,接下来就是分发请求,一旦应用被启动且所有服务提供者被注册,request 将会给路由器分发,路由器将会分发请求到路由或者控制器,同时运行所有路由指定的中间件。
laravel设计模式
依赖注入(DI):将类以传参的形式注入;解耦;
控制翻转(IOC): 将注入的类给外部调用;实现:依赖注入、工厂模式、服务定位;解耦,可扩展,易维护;
单例模式 (Singleton Pattern): Laravel 中的容器(Container)和应用实例(Application)等都是使用了单例模式,确保在整个应用程序生命周期中只存在一个实例。
工厂模式 (Factory Pattern): Laravel 的服务容器(Service Container)和服务提供者(Service Providers)等使用了工厂模式,用于动态创建对象实例。
策略模式 (Strategy Pattern): Laravel 的认证系统中使用了策略模式,允许开发者根据需要选择不同的认证策略。
观察者模式 (Observer Pattern): Laravel 的事件系统中使用了观察者模式,允许对象在状态改变时通知其他对象。
装饰器模式 (Decorator Pattern): Laravel 的中间件(Middleware)使用了装饰器模式,允许动态地为请求添加额外的功能。
门面模式 (Facade Pattern): Laravel 的门面(Facade)提供了一个简单的接口来访问复杂的子系统,隐藏了子系统的复杂性。
迭代器模式 (Iterator Pattern): Laravel 的集合对象(Collection)使用了迭代器模式,允许开发者在集合上进行迭代操作。
观察者模式 (Observer Pattern): Laravel 中的事件(Event)系统使用了观察者模式,允许对象订阅并监听事件的发生。
laravel依赖注入
依赖注入是一种设计模式,用于解决类的依赖关系;
将依赖的对象通过造函数、方法参数或属性注入到该类中;
从而解耦,更灵活
Container,bing()绑定在$binding,make()存在就返回对象,不存在就实例化再返回;然后通过反射解析controller需要哪些对象;
thinkphp
thinkphp5.1请求流程(生命周期)
单一入口public/index/php
composer 自动加载
实例化App类,设置容器实例和对象; 容器中的http类执行 加载配置,环境变量等 全局中间件 路由 局部中间件 回调或控制器 httpEnd事件
thinkphp5.1钩子函数,事件
thinkphp 门面
container注册了,make获取
thinkphp 中间件
thinkphp 依赖注入 Container
with的原理
在ThinkPHP中,使用模型查询时,可以通过with方法关联多个数据表,实现快速的数据查询和关联。
with方法的原理是使用了“预加载”(Eager Loading)的技术。通常在使用连表查询时,可能会导致N+1问题,即在查询主表时需要遍历从表的每一条记录,会产生额外的N条查询操作,导致查询效率低下。而使用预加载,则可以在查询主表时同时预先加载关联表的数据,避免了N+1问题。
在ThinkPHP中,with方法实现了两种预加载方法:
预先加载单个关联表的数据:$model->with('关联表名')。此时,会在查询主表的同时,预先加载关联表的数据,并以关联表名作为键将结果集存储到主表数据的关联属性中。
预先加载多个关联表的数据:$model->with(['关联表名1', '关联表名2', ...])。此时,会在查询主表的同时,预先加载多个关联表的数据,并以关联表名作为键将结果集存储到主表数据的关联属性中。
在使用with方法时,请注意避免关联表过多和查询数据量过大导致的性能问题。
安全
设置
public目录为唯一对外访问目录,不要把资源文件放入应用目录;开启表单令牌验证避免数据的重复提交,能起到CSRF防御作用;
使用框架提供的请求变量获取方法(
Request类param方法及input助手函数)而不是原生系统变量获取用户输入数据;对不同的应用需求设置
default_filter过滤规则(默认没有任何过滤规则),常见的安全过滤函数包括stripslashes、htmlentities、htmlspecialchars和strip_tags等,请根据业务场景选择最合适的过滤方法;使用验证类对业务数据设置必要的验证规则;
如果可能开启强制路由或者设置MISS路由规则,严格规范每个URL请求;
数据库安全
- 在确保用户请求的数据安全之后,数据库的安全隐患就已经很少了,因为数据操作默认使用了PDO预处理机制及自动参数绑定功能,请确保:
- 尽量少使用字符串查询条件,如果不得已的情况下使用手动参数绑定功能;
- 不要让用户输入决定要查询或者写入的字段;
- 不要让用户输入决定你的字段排序;
- 对于敏感数据在输出的时候使用hidden方法进行隐藏;
- 对于数据的写入操作应当做好权限检查工作;
- 写入数据严格使用field方法限制写入字段;
- 对于需要输出到页面的数据做好必要的XSS过滤;
- 如果你使用的是V5.1.10以下版本,建议尽快更新到该版本(或者以上版本)
上传
- 网站的上传功能也是一个非常容易被攻击的入口,所以对上传功能的安全检查是尤其必要的。
- 系统的
think\File提供了文件上传的安全支持,包括对文件后缀、文件类型、文件大小以及上传图片文件的合法性检查,确保你已经在上传操作中启用了这些合法性检查。
其它的一些安全建议:
- 对所有公共的操作方法做必要的安全检查,防止用户通过URL直接调用;
- 不要缓存需要用户认证的页面;
- 对用户的上传文件,做必要的安全检查,例如上传路径和非法格式;
- 对于项目进行充分的测试,不要生成业务逻辑的安全隐患(这可能是最大的安全问题);
- 最后一点,做好服务器的安全防护,安全问题的关键其实是找到你的最薄弱环
- 关注官方动态,及时更新;
hyperf
hyperf注意
不能用 $_GET/$_POST/$_REQUEST/$_SESSION/$_COOKIE/$_SERVER
通过容器获取的类都是单例
避免在魔术方法中切换协程(不包括__call,__callStatic)
不要将model注入
不能存在阻塞代码
不能通过全局变量储存状态
hyperf执行流程
php bin/hyperf.php start
composer自动加载
Container 读取 config/container.php,绑定类
读取配置
扫描类文件,根据注解获取路由和生成Proxy文件;
读取 config/autoload/server.php
启动swoole http服务,监听 request 事件;
请求来就,从路由配置中获取回调或控制器方法,然后执行;
返回结果
在项目中都是怎么用hyperf的?
了解hyperf中的依赖注入实现原理吗?
启动时container 绑定类; 扫描类文件生成proxy类,也判定到container里; @Inject注解注入;注入的都是单例;
注入是就能反射获取注入的类,然后获取对应对象
使用hyperf中的类是怎么实现的,是通过注解引入吗?
@Inject注解注入,然后就依赖注入;
workerman
workerman生命周期
合并数组有多少种方式?
array_merge
array_push
[...$a,$b]
foreach